Accepted at ACM SIGKDD 2026 · Jeju Island, South Korea Code: github.com/InfoLab-SKKU/VisionDES
Overview
Dynamic Ensemble Selection (DES) has proven powerful for tabular data, yet remained largely unexplored in computer vision. VisionDES bridges this gap — using deep model embeddings, FAISS-based nearest-neighbor search, and similarity-weighted competence estimation to dynamically pick the most reliable classifiers for each test image. The result: up to +20% robust accuracy under strong adversarial attacks, and +2–3% gains under distribution shift, with built-in instance-level interpretability.
| Metric | Result |
|---|---|
| Robust accuracy gain (adversarial attacks) | +20% |
| Accuracy improvement (distribution shift) | +2–3% |
| Benchmarks evaluated | ImageNet, CIFAR-10/100, MedMNIST (×3) |
| Attack types tested | PGD, MIM, C&W, AutoAttack |
The Problem with Static Ensembles
Modern computer vision systems underpin high-stakes applications — autonomous driving, medical imaging, industrial inspection, and more. To boost reliability, researchers routinely turn to ensemble learning: combining multiple models so their errors cancel out. But the dominant approach is fundamentally static.
Soft voting, hard voting, stacking — all of these aggregate every model’s prediction for every input, regardless of how appropriate each model is for that particular sample. Some models may excel at texture-rich images but fail on blurry ones. Some may be robust to PGD perturbations but brittle under distribution shift. Under a static ensemble, a compromised or miscalibrated model still gets a full vote.
“Every model contributes to every prediction — regardless of whether that model is reliable for this specific input.”
This rigidity becomes acutely dangerous under adversarial attack. Once a subset of ensemble members is compromised, the corrupted predictions propagate directly into the final decision with no mechanism to reduce their influence.
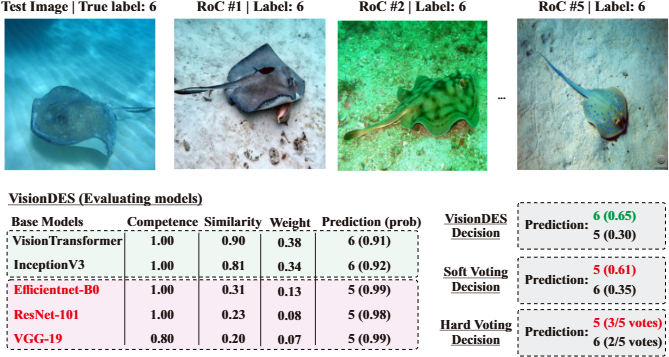
Figure 1. An example illustrating VisionDES’s advantage over static ensembles. Two base models (highlighted in red) have been attacked. Soft voting and hard voting produce wrong or uncertain results because the attacked models still carry full weight. VisionDES detects their reduced reliability via feature similarity and down-weights them — correctly predicting class 6.
The VisionDES Approach
VisionDES introduces a per-sample classifier selection strategy grounded in Dynamic Ensemble Selection (DES) — a paradigm previously applied almost exclusively to tabular data. This work is the first systematic adaptation of traditional DES for modern, high-dimensional vision tasks.
The core insight: instead of asking “which model is globally best?”, VisionDES asks “which models are most reliable for this specific image?” It answers by examining how each model behaves on semantically similar images — a Region of Competence (RoC) — and weighting contributions accordingly.
Key innovation: VisionDES uses DINO-based ViT embeddings and FAISS approximate nearest-neighbor search to construct a local Region of Competence in embedding space for each test sample — then dynamically selects and weights classifiers based on both their local accuracy and feature-space consistency.
Three Stages
Stage 1 — Training Diverse vision models (ViT, ResNet, EfficientNet, VGG, etc.) are trained. DINO embeddings of a validation set (DSEL) are indexed in a FAISS store for fast retrieval.
Stage 2 — Selection For each test image, its DINO embedding is computed and k=7 nearest neighbors are retrieved, defining the RoC. Classifiers are scored by their accuracy within that region using one of three selection rules:
- KNORA-U: includes any classifier that correctly labels at least one RoC sample, weighted by competence score.
- KNORA-E: the stricter rule — only classifiers that correctly label all RoC samples are selected.
- FIRE: handles indecision regions near class boundaries by requiring correct predictions from each class present in the RoC.
Stage 3 — Aggregation Selected classifiers are combined via similarity-weighted voting. Models whose internal representations diverge from the RoC mean are automatically down-weighted.
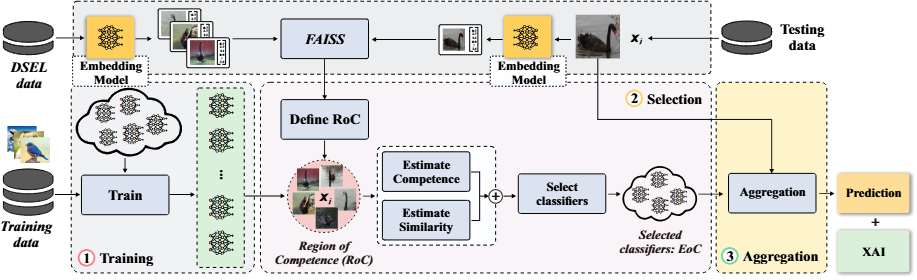
Figure 2. The VisionDES framework. At test time, the input image’s DINO embedding is used to retrieve a Region of Competence from the DSEL store. Competence and similarity scores are jointly computed and fused to produce the final weighted prediction.
Similarity-Weighted Competence
The most distinctive technical contribution of VisionDES is the similarity-weighted competence mechanism. Classical DES methods assign weights based solely on a classifier’s accuracy within the RoC. VisionDES adds a second signal: feature-space consistency.
For each classifier c_i, VisionDES computes the cosine similarity between the mean embedding of RoC samples (as seen through c_i’s penultimate layer) and the embedding of the test image itself. When a model has been adversarially perturbed, its internal representations become misaligned with those of clean neighboring samples — its similarity score drops, and so does its contribution.
The competence and similarity scores are fused via a convex combination:
w_i(t) = α_t · comp_i(t) + (1 − α_t) · s_i(t)
The mixing coefficient α is estimated adaptively per test sample, based on the relative variability of each signal across the ensemble. This lets similarity dominate when it provides a strong discriminative signal, while falling back to competence when similarity scores are homogeneous.
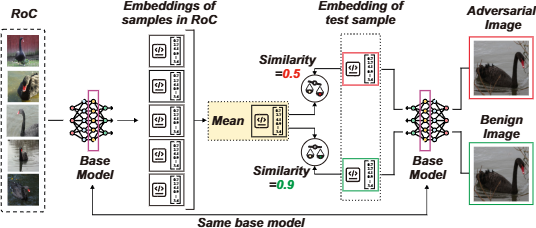
Figure 3. Similarity-weighted aggregation. For a benign image, a model’s internal representation closely matches the RoC mean — similarity ≈ 0.9. For an adversarially perturbed input, the same model’s representation drifts away — similarity drops to ≈ 0.5 — automatically reducing its weight in the ensemble decision.
Instance-Level Interpretability
Beyond robustness, VisionDES is inherently interpretable. Because classifier selection is explicit and per-sample, the framework reports — for any given prediction — exactly:
- Which models were selected
- Each model’s competence score and feature similarity score
- Each model’s assigned weight
- Each model’s top-5 class predictions
The Region of Competence is also visualized: the nearest validation samples are shown alongside their L2 distances to the test image, giving a concrete picture of the neighborhood in which the decision was made.

Figure 4. Interpretability output for a test image under benign conditions (top) and under a PGD adversarial attack on the ViT model (bottom). Under attack, the ViT’s feature similarity collapses from 0.847 to 0.062 — its combined weight is automatically reduced. Unattacked models maintain stable similarity and correct predictions. The RoC structure is largely preserved thanks to DINO’s robustness.
Experimental Results
VisionDES is evaluated across three settings — clean conditions, adversarial attacks, and distribution shift — on ImageNet, CIFAR-10, CIFAR-100, and three MedMNIST datasets (RetinaMNIST, BloodMNIST, DermaMNIST).
Clean Performance
Under standard conditions, VisionDES consistently matches or outperforms soft voting, hard voting, stacking, and DUS across all benchmarks. Notably, while soft and hard voting degrade when weaker models are added to the pool, VisionDES continues to improve — rising to 81.25% on ImageNet with six models, up from 80.95% with three. VisionDES can identify and down-weight weaker classifiers per-sample, rather than blending them in unconditionally.
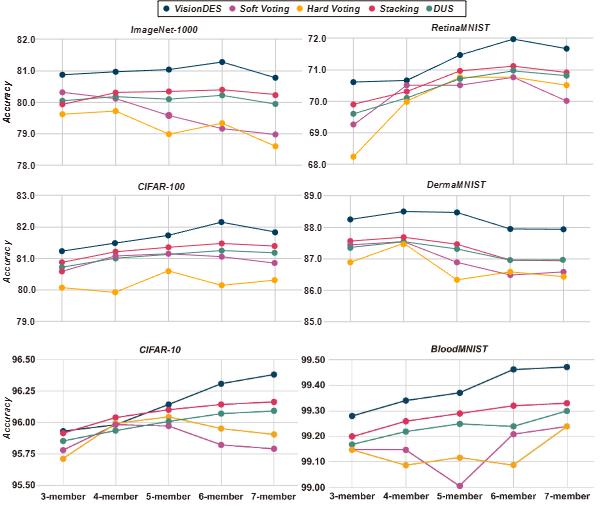
Figure 5. Accuracy as a function of ensemble pool size under clean conditions on ImageNet-1000, CIFAR-100, RetinaMNIST, and DermaMNIST. VisionDES consistently outperforms static methods and DUS, and uniquely continues to improve as weaker models are added.
Adversarial Robustness
We stress-test VisionDES with ensemble adversarial attacks, increasing the fraction of attacked base models from 1/6 to 6/6. When 83.3% of models are under PGD attack on ImageNet:
| Method | Accuracy |
|---|---|
| VisionDES | 51.72% |
| DUS | 39.45% |
| Hard Voting | 37.08% |
| Stacking | 33.53% |
| Soft Voting | 26.24% |
VisionDES also holds up across all four attack strategies. Under the C&W attack with all models targeted, VisionDES achieves 81.55% accuracy vs. 59.0% (soft), 61.9% (hard), 61.15% (stacking), and 64.8% (DUS) — an advantage exceeding 16 percentage points.
Attack order also matters: targeting stronger models first produces more transferable adversarial examples, strongly impacting static ensembles. VisionDES remains stable across both orderings, confirming that dynamic selection and similarity-weighted aggregation mitigate transferability effects.
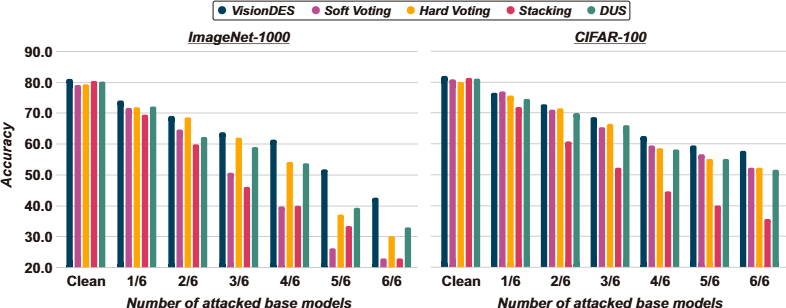
Figure 6. Ensemble robustness under PGD attack (ε=0.05 for ImageNet, ε=8/255 for CIFAR-100), with the number of attacked base models increasing from 1/6 to 6/6. VisionDES maintains a significantly higher accuracy floor as more models are compromised.
Increasing Perturbation Budget
As the adversarial budget grows, the performance gap widens. At ε=0.031, VisionDES maintains accuracy gains exceeding 13% over static ensembles. At ε=0.05 with half the pool attacked, VisionDES achieves over 20% higher accuracy than both static methods and DUS.
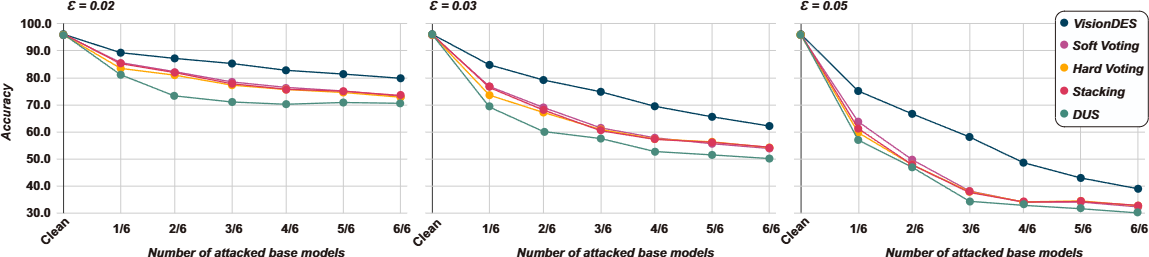
Figure 8. Ensemble accuracy on CIFAR-10 under PGD with ε ∈ {0.02, 0.031 (8/255), 0.05}, attacking models strongest-to-weakest. The advantage of VisionDES widens with both higher perturbation budget and more models attacked.
Distribution Shift
Under natural distribution shift (CIFAR-10 → CIFAR-10.1), the accuracy drop for VisionDES with seven models is 5.28%, compared to 6.36% (soft), 6.57% (hard), 6.77% (stacking), and 7.05% (DUS). Under synthetic Gaussian noise (σ=0.04), VisionDES sees an 11.1–11.9% drop versus 13–14% for static ensembles — consistently the smallest degradation across pool sizes.
Ablation Highlights
Why DINO? DINO-ViT achieves the highest cosine similarity between clean and perturbed embeddings (≈0.990–0.996), far outpacing ResNet-50 (0.894) and CLIP-ViT (0.969–0.979) under CNN-generated noise. DINO’s perturbation robustness keeps the Region of Competence stable even when base classifiers are under attack.
Neighborhood size.
k=7 provides a stable balance between local sensitivity (k=5) and neighborhood dilution (k=10). Label agreement is consistent across K-NN, HNSW, and FAISS backends, confirming that embedding quality — not retrieval algorithm — is the dominant factor.
Inference overhead. VisionDES requires ~71 ms per sample on ImageNet vs. ~28–36 ms for static methods. This is substantially reduced by precomputing base model predictions on the DSEL set. FAISS IndexIVFPQ can compress the embedding index to just 1.67 MB for memory-constrained deployment with no impact on inference time.
Larger pools. The benefits scale with ensemble size. An 8-member ensemble maintains accuracy above 80% across all attack ratios on CIFAR-10, outperforming both static methods and smaller VisionDES pools.
Conclusion
VisionDES demonstrates that the question for ensemble learning should not be “how many models?” but “which models, for this image?”. By introducing Dynamic Ensemble Selection to computer vision — grounded in robust DINO embeddings, FAISS-powered neighborhood search, and similarity-weighted competence estimation — VisionDES consistently outperforms static ensembles and uncertainty-based dynamic methods under clean, adversarial, and distribution-shifted conditions.
Beyond raw performance, the framework’s instance-level interpretability makes its decisions auditable and trustworthy, which is essential for safety-critical deployment. We see natural extensions toward multimodal ensembles, federated dynamic selection, and robust medical imaging systems.
We look forward to presenting this work at ACM SIGKDD 2026 in Jeju Island, South Korea.
Citation
@inproceedings{visiondes2026,
title = {VisionDES: Robust and Explainable Dynamic Vision Ensemble},
author = {Firuz Juraev, Mohammed Abuhamad, Shaker El-Sappagh, Simon S. Woo, Tamer Abuhmed},
booktitle = {Proceedings of the ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining (KDD)},
year = {2026}
}